I just can’t take it any more.
There is an incorrect perception floating around out there in Java world about the issue of mapping Java classes to SQL tables. This issue falls within a larger topic often referred to as the object-relational mapping (ORM) mismatch. This “mismatch” is based on the fact that Java is object-oriented, and SQL is not, so using Java classes to represent SQL tables involves some issues, and requires some clever work. That is true. But it’s led to a major misperception about SQL being supposedly “defective”. It is not, but this notion has crept its way into two books I’ve read lately, books by otherwise very smart people, published by major cutting edge IT book publishers.
(For the record, no, neither publisher in question is my own publisher, the incomparable McGraw-Hill Education and their awesome imprint with Oracle Corporation, Oracle Press.)
I’m not going to verbally quote either work, but the idea goes like this:
- To support persistence (storing data), you map a Java class (ex., “Customer”) to a corresponding SQL table (ex., “CUSTOMERS”)
- When creating two Java classes, it’s possible to design them with a many-to-many relationship to each other
- SQL doesn’t support the creation of tables with many-to-many relationships
- Therefore SQL is defective.
Uh – no.
Folks, the presence of a many-to-many relationship in your data model is a sign that you aren’t finished with your data model.
This isn’t a Java thing, or a SQL thing, it’s a real world thing.
It’s possible to build a defective data model in Java. You can do a lot of stupid stuff in Java. You can also build bad data models in SQL, and technically you actually can create a many-to-many in SQL, but it won’t work. That’s a good thing. I’ll explain shortly with an example.
But first, a word about the classic mismatch.
THE ORM MISMATCH
The authors of these two books I’ve read are Java developers first and foremost. I get that, and I know where they’re coming from. I’m a Java developer myself, and have been since Java was first introduced into the Oracle database as an alternative to PL/SQL, which I also love – so much that my first book was the official Oracle Press certification exam guide OCP Developer PL/SQL Program Units Exam Guide.
But about the time that book hit the shelves, I began working with Java, which had become available as an in-database alternative to PL/SQL. I soon thereafter began teaching Java. In fact, this is me with then-CEO of Sun Microsystems, on the first day I launched my first ever course in Java:

That was taken at the National Press Club. McNealy was hysterically funny that day and a great guy. He’s responsible for, and oversaw, a lot of great developments in Silicon valley that reverberate to this day – like Java.
And back at that time, the first question about Java was – how do we get Java and SQL to interact? That, after all, was Oracle’s whole point of embedding Java in the database.
Java has come a long, long way since then, and all for the better. There is a well established and growing library of packages and tools for implementing various interactions between Java and SQL. And at the heart of them all is often the same issue:
Java is object oriented, and SQL isn’t.
True. So what? Newcomers to Java act like this is some kind of ultimate nightmare scenario, a sign that SQL is out of sync with the world. Nonsense. SQL isn’t inherently object-oriented, but neither is your file system. And yet Java interacts with files just fine. Now granted, the idea behind SQL is more sophisticated than file systems. But on the other hand, SQL isn’t in the same category as a third-generation language (3GL) like Java, SQL is a fourth generation language (4GL). It might not support object-oriented dynamics, but neither does it clash with them. This is demonstrably obvious – otherwise we wouldn’t have JDBC, the Java Persistence API (JPA), and Hibernate. So the two can and do work together, and effectively. But it takes a bit of work; SQL doesn’t necessarily provide built-in support for all object-oriented concepts, such as inheritance. (Caveat: Inheritance actually can be supported in data modeling – see this article – and there’s a way to do it within SQL itself, sort of, but as to whether it’s helpful or not, that’s a different story, and perhaps the topic of a future blog post. Or book. Hm …. )
Frankly, when I hear about the “mismatch” between Java and SQL, I think of the issue of transactions, that’s the only real issue to me. The object life cycle and nature of Java is such that it introduces challenges in the way persistence to the database is best done in a multi-user/multi-threaded environment.
But let’s get back to topic and dispel this “SQL is defective” myth.
DATA MODELING
Data modeling is the act of representing real world business processes through diagrams of the things (“entities”) that comprise a real world process, and the relationships (or “associations”) among those entities. The most obvious entities are easy to identify – customers, products, office buildings, vendors, cars, etc. But the more abstract entities are not always so obvious – work schedules, change orders, reservations, that sort of thing. This is where the importance of understanding many-to-many relationships can be very helpful.
AN EXAMPLE
I’m going to use an example taken from the airline industry, as I’ve been meeting lately with Lisa Ray, a lifelong aviation data expert closely involved with a series of legacy migrations in that area. (And for the record, she fully gets this.)
Let’s start with two obvious entities:
- Planes – as in “individual planes”, not just types of planes.
- Pilots – individual people.
Every one plane might be flown by more than one pilot. Every one pilot will be qualified to fly more than one plane. Sounds like a many-to-many relationship, right? And as you might know, an entity-relationship diagram illustrates the “many” side of a relationship with the classic crow’s-feet line:
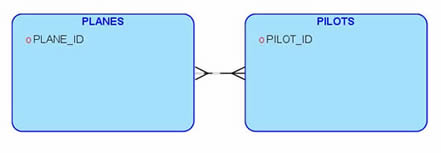
So that’s our initial logical diagram for these two entities.
Now folks, this blog post is not going to be a complete tutorial on how to perform data modeling, but we will explore one key aspect of modeling: whenever you encounter a many-to-many relationship, you ALWAYS transform it using the following steps:
- Add a third entity in between – “Entity_3” in our diagram below.
- Create foreign keys within the new entity for the primary keys of the existing entities – in this case, PLANE_ID as a foreign key to the PLANES entity’s PLANE_ID primary key, and PILOT_ID as a foreign key to the PILOTS entity’s PILOT_ID primary key.
- Establish “one-to-many” relationships between the new entity and the existing entities, using the “single-line” to indicate the “1” side, and the “crow’s foot” to indicate “many” side of the relationship.
Like this:

The reason we do that is simple: the presence of a many-to-many relationship is a clear indicator that something else goes in between the two entities. The question is not “if” something belongs there. Something does belong there. The only question is – what exactly is it?
In our example, it’s going to be something like a “roster”, or a “schedule”, or “flight assignments”, or “rentals”:

Call it what you will, but something goes in between and it must be included in your data model. That new entity will have its own attributes. Perhaps:
- A start and end date to the time of assignment
- A name of a key staff member authorized to approve the assignment
Who knows what might be there? But something is there, and the presence of the many-to-many relationship is your clue to its existence.
That third entity is often a bit more abstract. You can see pilots and planes, but a “flight assignment” isn’t necessarily as obvious. But it’s an important entity in the data model nonetheless.
One more point: this third entity isn’t some necessary crutch to get around a “SQL defect”. I can’t believe what I’ve read in certain Java books that suggest such a thing. No. This third entity is a real world “thing” that definitely exists in order to enable the relationship with the real world, and it’s up to you to identify it. Whether you figure it out or not, it exists nonetheless.
The rule is simple: no complete data model exists with any “many-to-many” relationships. If such are present, you aren’t done modeling yet.
So now that you understand this, imagine reading a Java manual in which someone explains that SQL is “defective” because it “doesn’t support many-to-many relationships”.
No.
Now you know!
O’Hearn is the Java leader of the only officially recognized JUG for the DC metro area. He is also the author of the first-ever expert-level certification exam guide from Oracle Press, titled OCA Oracle Database SQL Certified Expert Exam Guide (Exam 1Z0-047). The 2nd edition of his SQL Expert book, revised for Oracle 12c, is due out in 2016.